SQL¶
SQL 分类¶
DDL– Data Definition LanguageDQL– Data Query LanguageDML– Data Manipulation LanguageDCL– Data Control LanguageTCL– Transaction Control Language
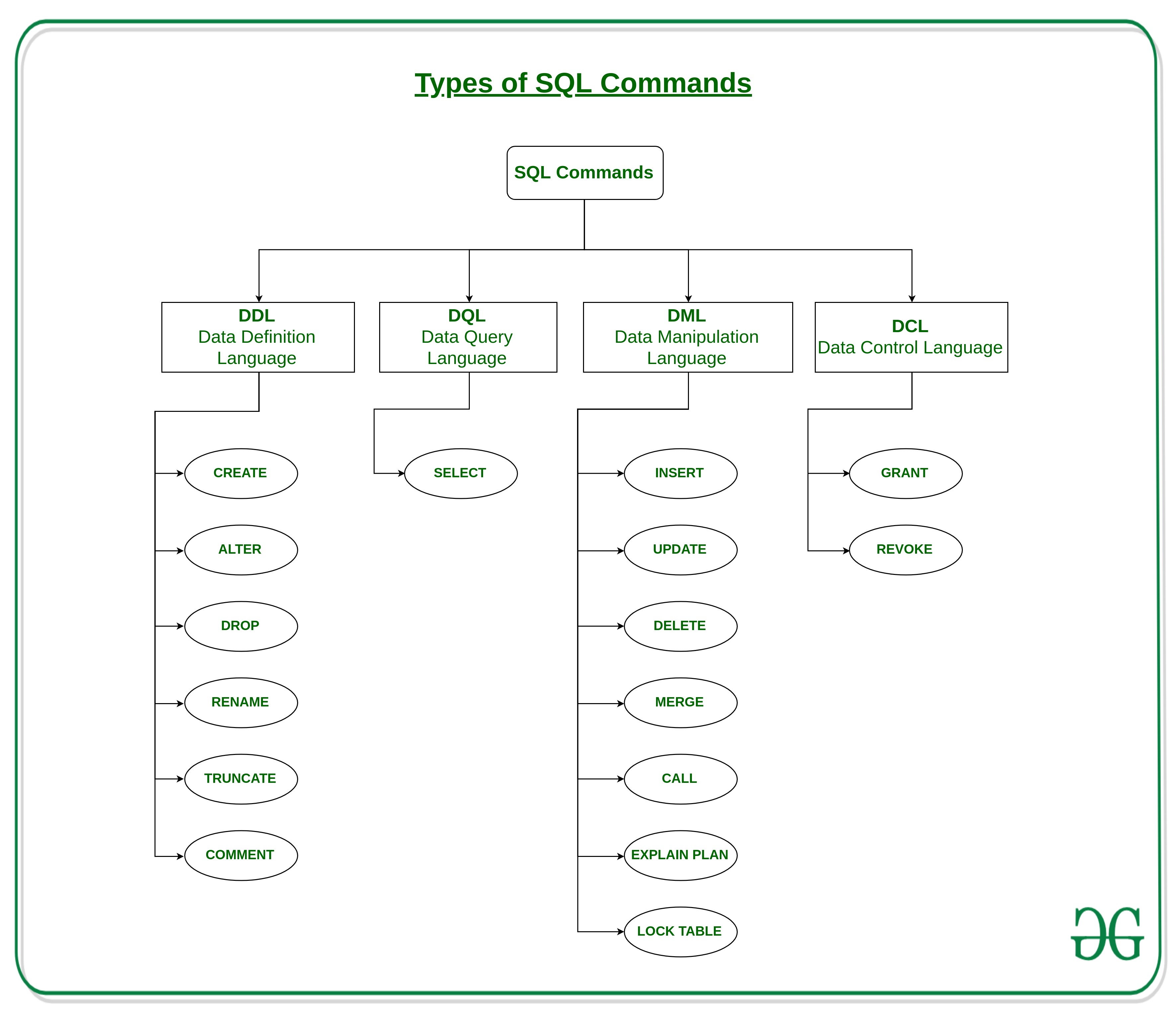
DDL¶
DDL 类语法都包含 TABLE 关键字, CREATE TABLE, ALTER TALBE etc
创建表¶
CREATE TABLE mytable (
id INT NOT NULL AUTO_INCREMENT COMMENT 'int 类型,不为空,自增',
col1 INT NOT NULL DEFAULT 1 COMMENT 'int 类型,不可为空,默认值为 1,不为空',
col2 VARCHAR(45) NULL COMMENT '变长字符串类型,最长为 45 个字符,可以为空',
col3 DATE NULL COMMENT '日期类型,可为空',
PRIMARY KEY (`id`) COMMENT '设置主键为 id'
);
修改表¶
参考 alter table
/* 添加列 */
ALTER TABLE mytable ADD col_name CHAR(20);
ALTER TABLE mytable ADD col_name CHAR(20) AFTER col_name2;
/* 删除列 */
ALTER TABLE mytable DROP COLUMN col_name;
/* 修改列 */
ALTER TABLE mytable MODIFY COLUMN col_name datatype;
/* 重命名表 */
ALTER TABLE t1 RENAME t2;
/*
To change column ``a`` from INTEGER to TINYINT NOT NULL (leaving the name the same),
and to change column ``b`` from CHAR(10) to CHAR(20) as well as renaming it from ``b`` to ``c``:
*/
ALTER TABLE `t2` MODIFY `a` TINYINT NOT NULL, CHANGE `b` `c` CHAR(20);
DQL¶
查询语法¶
SELECT [DISTINCT|ALL ] { * | [fieldExpression [AS newName]}
FROM tableName [alias]
[WHERE condition]
[GROUP BY fieldName(s)] [HAVING condition]
ORDER BY fieldName(s) [ASC | DESC]
[LIMIT {[offset,] row_count | row_count OFFSET offset}]
通配符
1. `%` 匹配 `>=0` 个任意字符; 2. `_` 匹配 `==1` 个任意字符; 3. `[ ]` 可以匹配集合内的字符,例如 `[ab]` 将匹配字符 a 或者 b。用脱字符 ^ 可以对其进行否定,也就是不匹配集合内的字符。
SELECT * FROM mytable WHERE col LIKE '[^AB]%'; -- 不以 A 和 B 开头的任意文本
分组
在 ``sql_mode=only_full_group_by`` 模式下除了汇总字段外, SELECT 语句中的每一字段都必须在 GROUP BY 子句中给出; 例如 GROUP BY 只有 `col` 字段, SELECT 中出现了 `col2` 会引起报错 SELECT col, col2, COUNT(*) AS num FROM mytable GROUP BY col; 允许 SELECT 中出现汇总函数 SELECT COUNT(*) FROM person2 GROUP BY email; SELECT COUNT(id) FROM person2 GROUP BY email;
SELECT col, COUNT(*) AS num FROM mytable WHERE col > 2 GROUP BY col HAVING num >= 2 ORDER BY num; /* The students with both same SUBJECT and YEAR are placed in same group. */ SELECT SUBJECT, YEAR, Count(*) FROM Student GROUP BY SUBJECT, YEAR;
子查询
/* 子查询中只能返回一个字段的数据。*/ SELECT * FROM mytable1 WHERE col1 IN (SELECT col2 FROM mytable2); /* 外层查询出来的每一个用户都会执行一遍内层的子查询统计订单数量 */ SELECT name, (SELECT COUNT(*) FROM Orders WHERE Orders.cust_id = Customers.cust_id) AS orders_num FROM Customers ORDER BY name;
连接(join)
- 通常连接要比子查询性能更好
- JOIN Syntax
- 连接类型
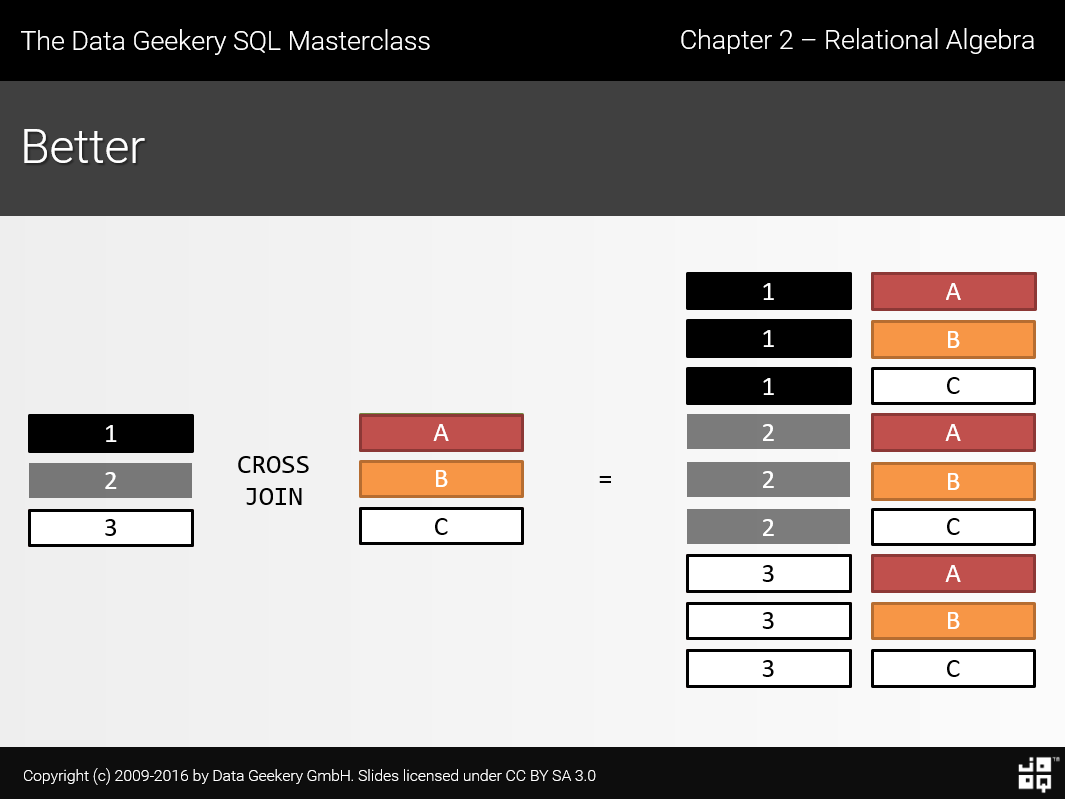
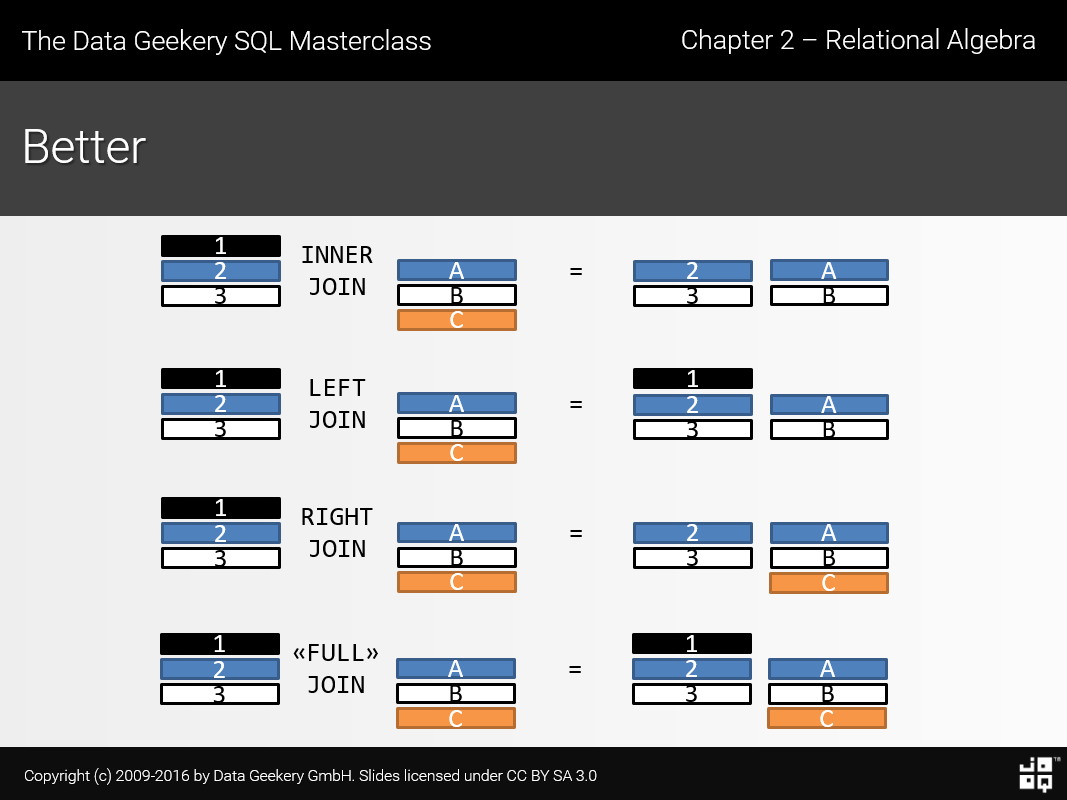
join example
SELECT m.member_id, m.name member, c.committee_id, c.name committee FROM members m INNER JOIN committees c ON c.name = m.name; /* If the join condition uses the equal operator (=) and the column names in both tables used for matching are the same, you can use the ``USING`` clause instead: */ SELECT m.member_id, m.name member, c.committee_id, c.name committee FROM members m INNER JOIN committees c USING(name);
自连接(连接自身表,特殊的内连接)
/* 一张员工表,包含员工姓名和员工所属部门,要找出与 Tom 处在同一部门的所有员工姓名。*/ /* 子查询版本 */ SELECT name FROM employee WHERE department = ( SELECT department FROM employee WHERE name = "Tom" ); /* 自连接版本 */ SELECT e1.name FROM employee AS e1 INNER JOIN employee AS e2 ON e1.department = e2.department AND e2.name = "Tom"; /* 自连接版本2 */ SELECT p1.* FROM Person p1, Person p2 WHERE p1.Email = p2.Email AND p1.Id > p2.Id;
自然连接
自然连接是把同名列通过等值测试连接起来的,同名列可以有多个。 内连接和自然连接的区别:内连接提供连接的列,而自然连接自动连接所有同名列 。
SELECT A.value, B.value FROM tablea AS A NATURAL JOIN tableb AS B;
组合(union)
使用 UNION 来组合两个查询,如果第一个查询返回 M 行,第二个查询返回 N 行,那么组合查询的结果一般为 M+N 行。 每个查询必须包含相同的列、表达式和聚集函数。 默认会去除相同行,如果需要保留相同行,使用 UNION ALL。 只能包含一个 ORDER BY 子句,并且必须位于语句的最后。
SELECT col FROM mytable WHERE col = 1 UNION SELECT col FROM mytable WHERE col = 2;