索引¶
索引基础¶
- 什么是索引?
- 存储引擎用于快速找到记录的 一种数据结构。
- 索引的目的在于提高查询效率。
- 类比一本书的 索引 目录部分。
- MySQL 存储引擎先在索引中找到对应值,然后根据匹配的索引记录找到对应的数据行。
/* 如果在 ``actor_id`` 列上建有索引,则 MySQL 将使用该索引找到 ``actor_id`` 为 5 的行;先在索引上按值查找,然后返回所有包含该值的数据行 */ SELECT first_name FROM sakila.actor WHERE actor_id=5;
- 什么条件下使用索引?
- 对于非常小的表、大部分情况下简单的全表扫描比建立索引更高效;
- 对于中到大型的表,索引就非常有效;
- 但是对于特大型的表,建立和维护索引的代价将会随之增长。 这种情况下,需要用到一种技术可以直接区分出需要查询的一组数据, 而不是一条记录一条记录地匹配,例如可以使用分区技术。
- TODO: 什么量级算小表,中大表,特大表?
如何建立索引?
索引的顺序如何?
索引类型¶
Note
MySQL 中,索引在存储引擎层而不是服务器层实现。所以没有统一索引标准:不同存储引擎的索引 工作方式不同,也不是所有存储引擎都支持所有类型的索引。
需要一种数据结构能够:每次查找数据时把磁盘IO次数控制在一个很小的数量级,最好是常数数量级。
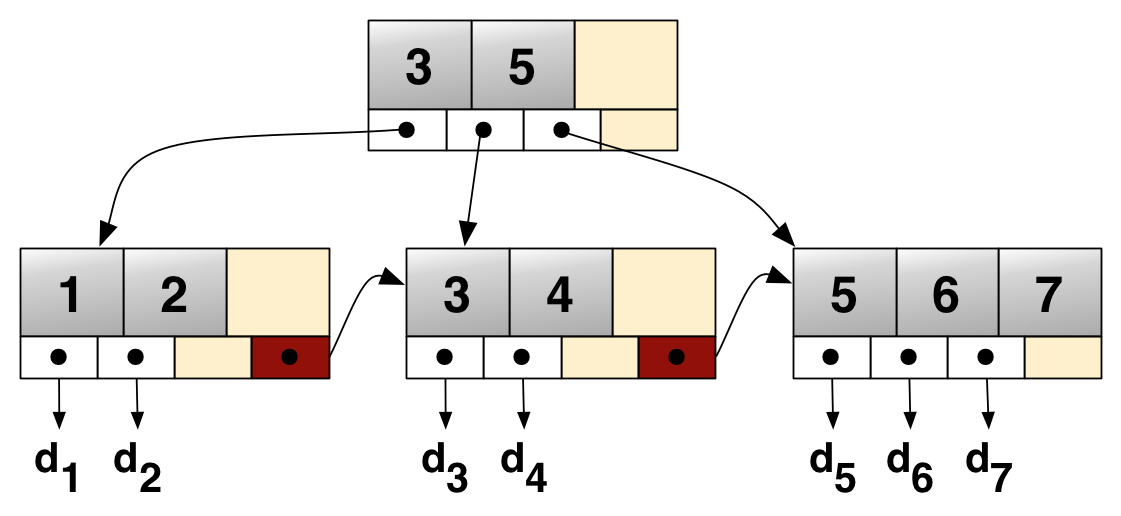

索引原则¶
Note
- 最左前缀匹配原则(Leftmost Prefix),非常重要的原则,mysql 会一直向右匹配直到遇到范围查询
(>、<、between、like)就停止匹配, 比如a = 1 and b = 2 and c > 3 and d = 4如果建立(a,b,c,d)顺序的索引,d 是用不到索引的, 如果建立(a,b,d,c)的索引则都可以用到,a,b,d 的顺序可以任意调整, 参考 联合索引。 =和in ``可以乱序,比如 ``a = 1 and b = 2 and c = 3建立(a,b,c)索引可以任意顺序, mysql的查询优化器会帮你优化成索引可以识别的形式。- 尽量选择区分度高的列作为索引,区分度的公式是
count(distinct col) / count(*), 表示字段不重复的比例,比例越大我们扫描的记录数越少,唯一键的区分度是1,而一些状态、 性别字段可能在大数据面前区分度就是0,那可能有人会问,这个比例有什么经验值吗? 使用场景不同,这个值也很难确定,一般需要join的字段我们都要求是0.1以上,即平均1条扫描10条记录。 - 索引列不能参与计算,保持列“干净”,比如
from_unixtime(create_time) = "2014-05-29"就不能使用到索引, 原因很简单,b+树中存的都是数据表中的字段值,但进行检索时,需要把所有元素都应用函数才能比较,显然成本太大。 所以语句应该写成create_time = unix_timestamp('2014-05-29')。 - 尽量的扩展索引,不要新建索引。比如表中已经有a的索引,现在要加(a,b)的索引,那么只需要修改原来的索引即可。